Random Peptide Library: Harnessing Diversity for Breakthrough Solutions
In the world of molecular biology and drug discovery, the ability to explore a vast range of molecular interactions is crucial for finding new therapeutic targets, diagnostic markers, and understanding complex biological processes. One of the most powerful tools for achieving this is the random peptide library. This method allows researchers to create a diverse collection of peptide sequences and screen them for their ability to bind to specific targets, offering breakthrough solutions in biotechnology, pharmaceutical research, and diagnostics.
In this article, we will delve into what a random peptide library is, how it works, and the diverse applications that are driving innovation in molecular biology and beyond.
What is a Random Peptide Library?
A random peptide library is a collection of peptides (short chains of amino acids) that are synthesized in such a way that the amino acid sequences are randomly generated. These libraries can contain billions of unique peptide sequences, each representing a different combination of amino acids. The diversity of sequences in these libraries is a key feature that makes them highly valuable in research, as they provide a broad range of peptides with potentially novel and useful biological activities.
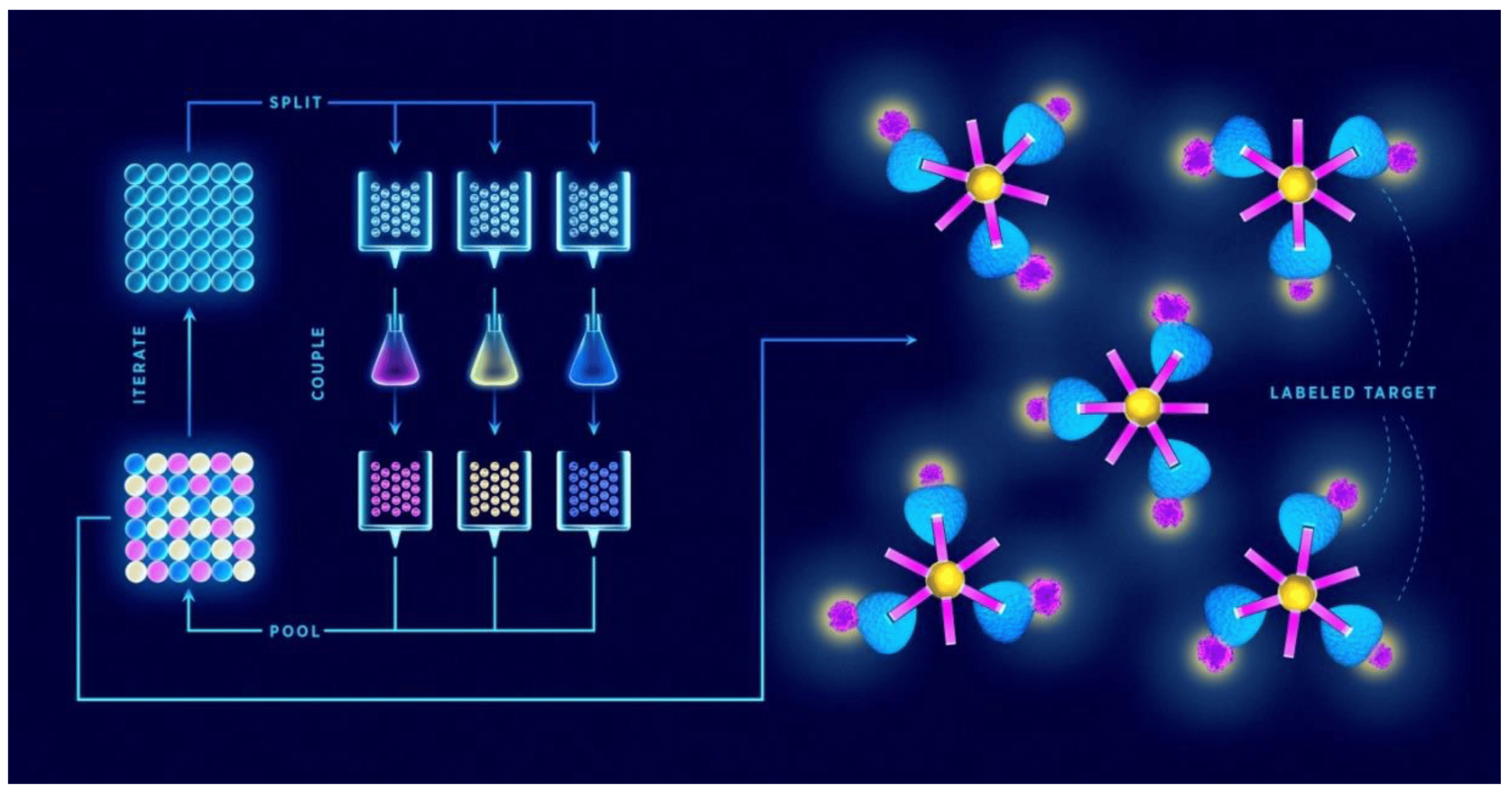
The process of creating a random peptide library typically involves using combinatorial chemistry or biological methods such as phage display, where peptides are displayed on the surface of bacteriophages (viruses that infect bacteria). This allows researchers to screen the library for peptides that interact with specific biological targets, such as proteins, receptors, or other molecules of interest.
How Does a Random Peptide Library Work?
The process of using a random peptide library generally follows a series of steps:
1. Library Construction
To create a random peptide library, researchers use synthetic biology or recombinant DNA techniques to generate a wide variety of peptides. Each peptide is typically composed of 5 to 20 amino acids, chosen randomly from the 20 naturally occurring amino acids. The peptides are then encoded in a DNA sequence, which is inserted into a phage, bacteria, or yeast, allowing the peptides to be displayed on the surface of these organisms.
2. Screening (Selection)
The next step involves screening the peptide library for peptides that interact with a specific target. This process, known as panning, often involves incubating the library with the target molecule, such as a protein, enzyme, or receptor. Peptides that bind tightly to the target are then isolated using techniques like magnetic separation, affinity chromatography, or other methods designed to capture bound peptides.
3. Amplification
After identifying the peptides that bind to the target, the selected peptides are amplified by allowing the host organisms (e.g., bacteria or phages) to replicate. This step ensures that the selected peptides are enriched in the library for further analysis.
4. Analysis and Identification
Finally, the isolated peptides are sequenced to determine their amino acid composition. Researchers then analyze the sequences to understand their binding properties, biological activities, and potential for use in therapeutic applications or diagnostics.
Advantages of Random Peptide Libraries
The use of random peptide libraries offers several advantages that make them invaluable in the fields of drug discovery, molecular biology, and biotechnology:
1. High Diversity and Coverage
One of the most significant advantages of random peptide libraries is the sheer diversity they provide. With billions of different peptides in a single library, the chances of finding a peptide that interacts specifically with a target molecule are greatly increased. This diversity enables researchers to explore a wide range of possible interactions, including those that may be overlooked in more traditional approaches.
2. High-Throughput Screening
Random peptide libraries allow for high-throughput screening, meaning that large numbers of peptides can be tested in parallel, saving time and resources in the discovery process. This is especially important in drug discovery, where speed and efficiency are key to identifying lead compounds for further development.
3. Cost-Effective
Creating a random peptide library is relatively inexpensive compared to other methods of drug discovery, such as high-throughput chemical screening or monoclonal antibody production. Additionally, the ability to screen a large number of peptides simultaneously reduces the cost per screening.
4. Customizable and Adaptable
Random peptide libraries are highly customizable, meaning that researchers can tailor the libraries to include specific sequences or functional groups that may enhance the chances of finding the desired biological activity. This flexibility makes them adaptable to a wide range of applications in both basic research and applied sciences.
5. No Need for Pre-existing Knowledge
Unlike traditional drug discovery methods that often require knowledge of the target’s structure or function, random peptide libraries allow researchers to discover peptides that bind to targets without needing detailed prior information about the target. This makes them an ideal tool for discovering novel targets or biomarkers in previously unexplored areas of biology.
Applications of Random Peptide Libraries
Random peptide libraries have a wide range of applications across various fields of research, offering innovative solutions to complex biological challenges. Some of the most important applications include:
1. Drug Discovery and Development
Random peptide libraries play a crucial role in drug discovery by identifying novel peptides that can act as lead compounds for the development of new therapeutics. By screening for peptides that bind to specific proteins or receptors involved in disease processes, researchers can uncover new drug candidates with high specificity and efficacy. These peptides can serve as potential inhibitors, activators, or modulators of disease-related targets.
2. Target Identification and Validation
In many cases, diseases are driven by the abnormal activity of certain proteins or receptors. Random peptide libraries can be used to identify peptides that bind to these targets, helping researchers validate the role of specific proteins in disease. This information is critical for the development of targeted therapies that specifically address the underlying causes of disease.
3. Diagnostics and Biomarker Discovery
Peptides from random peptide libraries can also be used as diagnostic tools. By identifying peptides that specifically bind to disease biomarkers, researchers can develop diagnostic assays for early detection of diseases such as cancer, autoimmune disorders, or infectious diseases. These peptides can be used to create biosensors or other diagnostic platforms.
4. Immunotherapy
Random peptide libraries are widely used in the development of immunotherapies, such as vaccines or immune checkpoint inhibitors. By screening for peptides that trigger an immune response, researchers can identify candidates for vaccine development or therapies that boost the body’s immune system to fight cancer or infections.
5. Protein-Protein Interaction Studies
Understanding protein-protein interactions is essential for unraveling cellular processes and disease mechanisms. Random peptide libraries can be used to identify peptides that bind to specific regions of proteins, allowing researchers to study protein interactions and the molecular basis of cellular processes.
6. Antibody Development
Peptides from random peptide libraries can be used to identify epitopes (the part of the antigen that is recognized by the immune system) for antibody development. This is particularly useful in the production of monoclonal antibodies, which are widely used in diagnostics and therapeutics.
Future of Random Peptide Libraries
As technology continues to advance, the potential applications of random peptide libraries are expanding. Improvements in sequencing technologies, high-throughput screening methods, and computational tools are making the creation and analysis of random peptide libraries more efficient and effective. The integration of artificial intelligence and machine learning is also expected to further accelerate the discovery of novel peptides and their applications in drug discovery, diagnostics, and beyond.
Conclusion
Random peptide libraries are transforming molecular biology by providing a vast and diverse pool of peptides that can be screened for their ability to interact with specific biological targets. With applications ranging from drug discovery to diagnostics and immunotherapy, these libraries are driving innovation in the development of new treatments and technologies. By harnessing the power of diversity, random peptide libraries are paving the way for breakthrough solutions in biomedical research and biotechnology.





